The Bluestocking Corpus: Letters by Elizabeth Montagu, 1730s-1780s
R
networks
ggplot
womens history
Author
Sharon Howard
Published
28 March 2020
Introduction
This post for Women’s History Month 2020 explores the Bluestocking Corpus of Elizabeth Montagu’s letters, created by Anni Sairio.*
This first version of the Bluestocking Corpus consists of 243 manuscript letters, written by the ‘Queen of the Blues’ Elizabeth Montagu between the 1730s and the 1780s. Elizabeth Montagu (née Robinson, 1718-1800) was one of the key figures of the learning-oriented Bluestocking Circle in eighteenth-century England. She was a literary hostess, coal mine owner and patron of arts who published a popular essay in defense of Shakespeare against Voltaire’s criticism. In its current form the corpus contains 183,000 words
A warning: I know virtually nothing about Elizabeth or her circle, so everything that follows is likely to be a) obvious or worse b) infuriatingly stupid and wrong to better-informed researchers. But I wanted to take a look at the data Anni has so generously created and made available, and show some of the things that could be done with it.
*The Bluestocking Corpus: Private Correspondence of Elizabeth Montagu, 1730s-1780s. First version. Edited by Anni Sairio, XML encoding by Ville Marttila. Department of Modern Languages, University of Helsinki. 2017. 28 March 2020. http://bluestocking.ling.helsinki.fi/
Code
# r packageslibrary(tidyverse)theme_set(theme_minimal()) # set preferred ggplot theme library(lubridate) # nice date functionslibrary(scales) # additional scaling functions mainly for ggplot (eg %-ages)library(knitr) # kable (nicer tables)library(kableExtra) library(tidytext)library(tidylo)library(patchwork)library(ggrepel)library(ggthemes) # more good colours n stuff### devtools::install_github("hrbrmstr/waffle")library(waffle)library(hrbrthemes)# https://github.com/wilkox/treemapifylibrary(treemapify)library(widyr)library(tidygraph) library(ggraph)library(igraph)# get the data #metadata - extracted from .txt and .xml files (the latter using XQuery)blue_metadata <-read_tsv(here::here("site_data/bluestocking/bluestocking_metadata_20200323.tsv"))#plain text - extracted from .xml files using BeautifulSoupblue_text <-read_tsv(here::here("site_data/bluestocking/bluestocking_plain_text_20200323.tsv"))# names mentioned in the textsblue_names <-read_tsv(here::here("site_data/bluestocking/bluestocking_mentioned_names_20200323.tsv")) %>%inner_join(blue_metadata %>%select(docid, date_year, decade, recipient_short, recipient_gender, recipient_type, n_words), by="docid") %>%mutate(mention_title =str_trim(str_extract(name, "^[^ ]+"))) %>%mutate(mention_title_gender =case_when( mention_title %in%c("Miss", "Mrs", "Lady", "Ldy", "Duchess", "Dutchess", "Countess") ~"female", mention_title %in%c("Mr", "Lord", "Ld", "Dr", "Sir", "Sr", "Duke", "Earl") ~"male" ))blue_recipients <-blue_metadata %>%count(recipient_id, recipient_short, recipient_type, recipient_gender, name="n_letters")blue_text_words <- blue_text %>%select(docid, text) %>%unnest_tokens(word, text)blue_recipient_words <-blue_text_words %>%inner_join(blue_metadata %>%select(docid, date_year, decade, recipient, recipient_short, recipient_id, recipient_gender, recipient_type, n_words) %>%group_by(recipient_short, recipient_id, recipient_type, recipient_gender) %>%mutate(total_words=sum(n_words), n_letters=n()) %>%ungroup() , by="docid") blue_recipient_words_tfidf <-blue_recipient_words %>%filter(n_letters>5) %>%count(recipient_short, recipient_id, total_words, n_letters, recipient_gender, word, sort=TRUE) %>%bind_tf_idf(word, recipient_short, n)blue_gender_log_odds <-blue_recipient_words %>%count(recipient_gender, word, sort=TRUE) %>%bind_log_odds(recipient_gender, word, n)blue_names_cor <-blue_names %>%distinct(name, docid) %>%add_count(name) %>%filter(n>3) %>%pairwise_cor(name, docid, upper=F, sort=T)blue_female_recipients_names_cor <-blue_names %>%filter(recipient_gender=="female") %>%distinct(name, docid, recipient_gender) %>%add_count(name) %>%filter(n>2) %>%pairwise_cor(name, docid, upper=F, sort=T)blue_names_top_fr_tab <-with(blue_names %>%filter(recipient_gender=="female") %>%distinct(docid, recipient_gender, name) %>%count(name, recipient_gender, sort=TRUE) %>%top_n(24, n) %>%inner_join(blue_names, by=c("name", "recipient_gender")) %>%distinct(docid, name) %>%arrange(docid, name),table(docid, name))
Overview
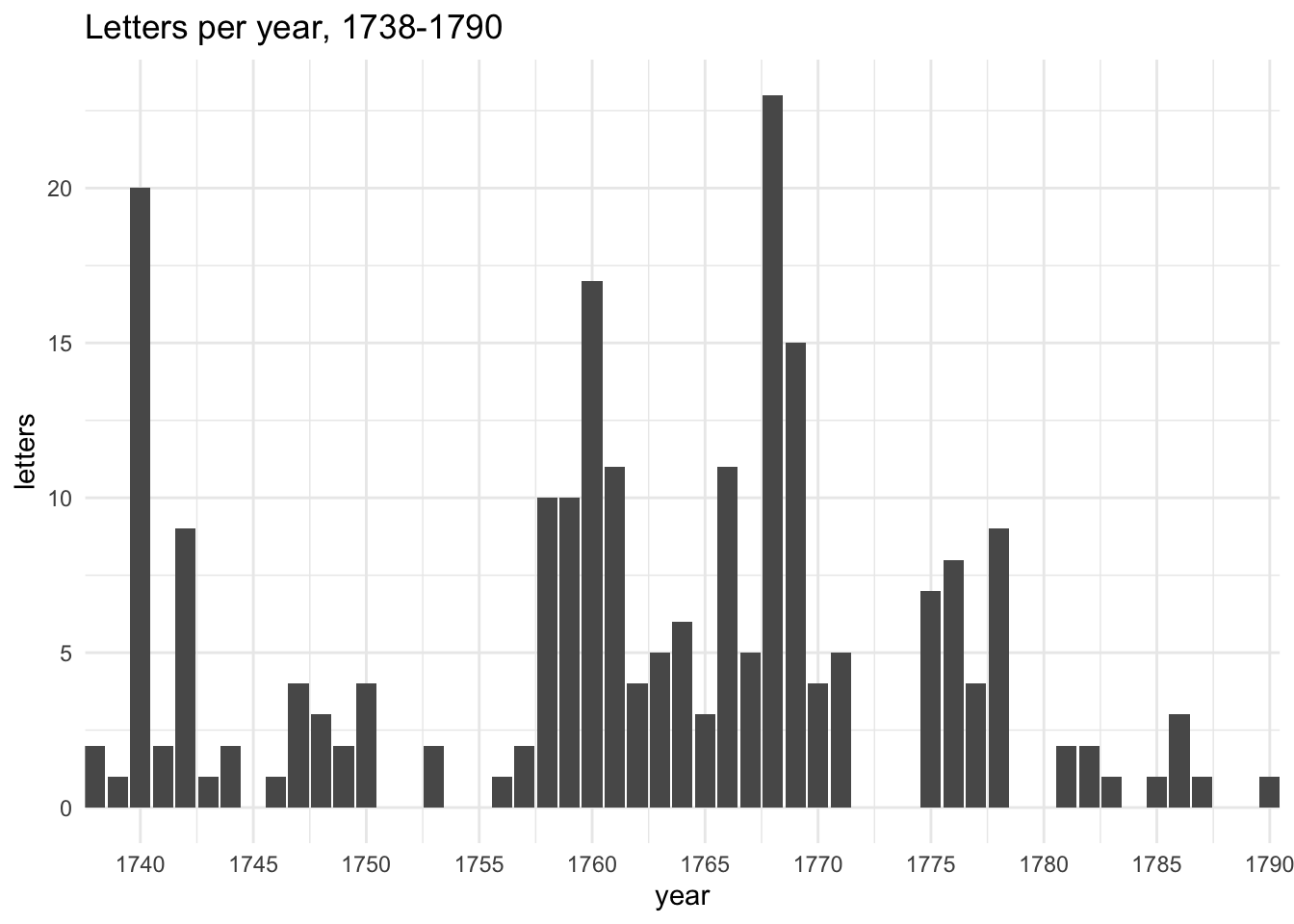
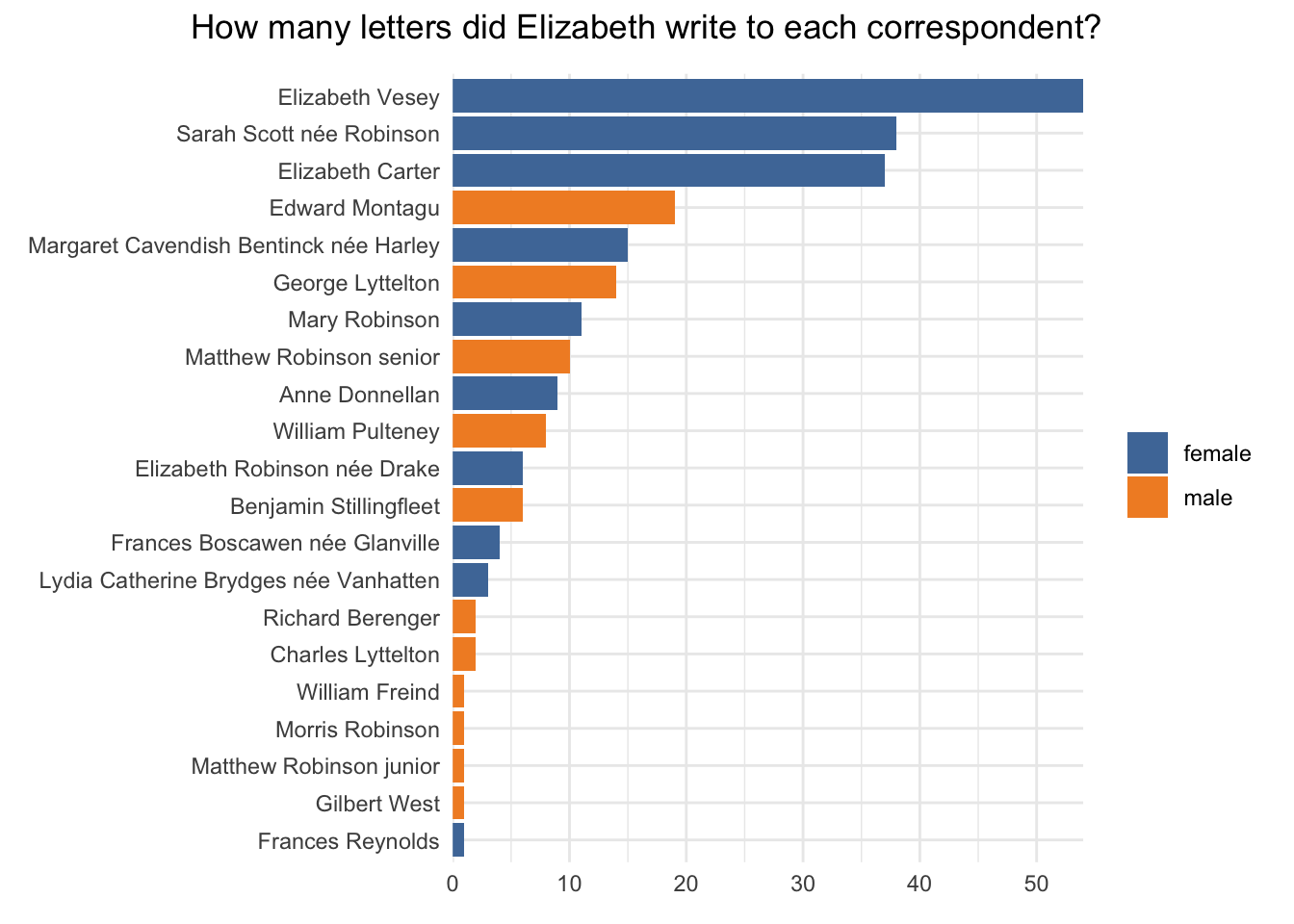
There are 243 letters in the corpus, and 21 different recipients. I’ve extracted metadata from the marked-up letters, as well as a set of plain text versions for textmining.
Most letters were sent during the 1760s but the numbers are very variable from one year to the next. (This excludes 19 undated letters.)
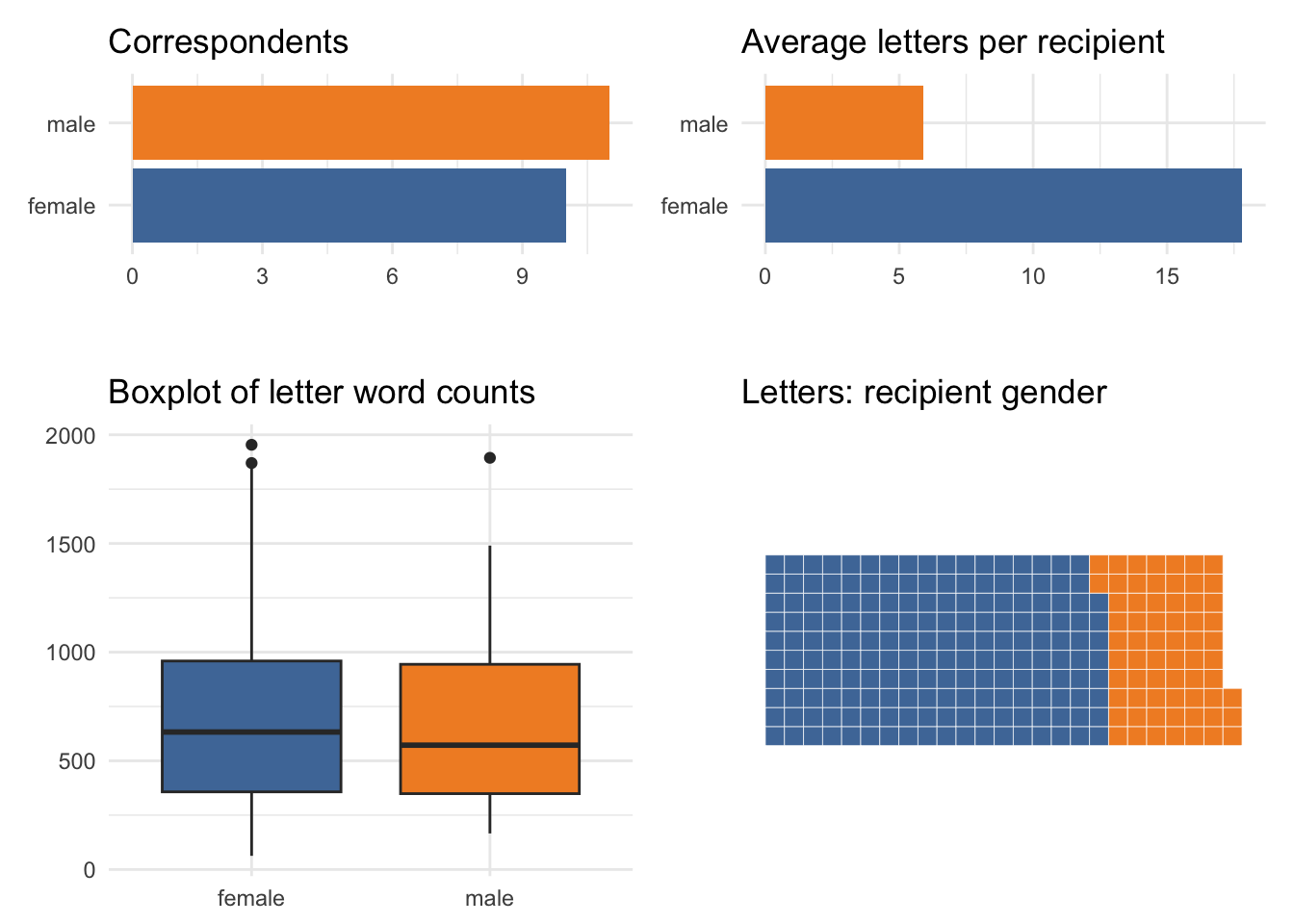
There are some substantial differences between letters sent to women and to men. While there were 10 female and 11 male correspondents, Elizabeth sent 178 letters to women (ave 17.8 per recipient) and only 65 to men (5.9 per recipient). On average, letters to women were also longer (mean 705.5 words per letter cf. 675.3 for men; median 632.5 for women and 572.0 for men).
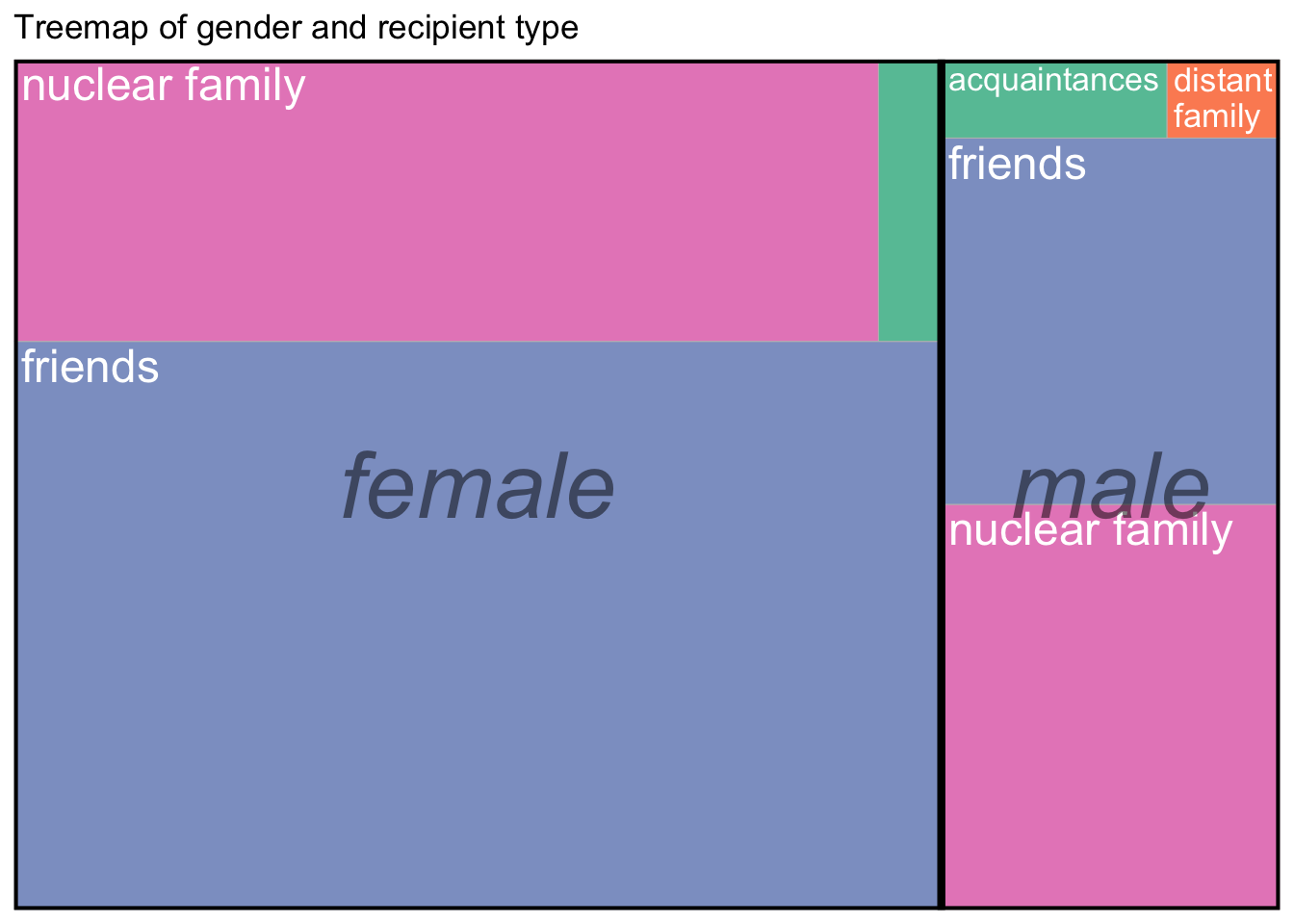
A further gendered difference can also be found in the type of correspondents (as tagged by Anni), notably the different balance of letters sent to family or friends.
blue_metadata %>%count(recipient_short, recipient_gender) %>%mutate(recipient_short =fct_reorder(recipient_short, n)) %>%ggplot(aes(x=recipient_short, y=n, fill=recipient_gender)) +geom_col(#show.legend = FALSE ) +coord_flip() +scale_y_continuous(expand =c(0,0)) +labs(y =NULL, x =NULL, fill=NULL) +scale_fill_tableau() +plot_annotation(title="How many letters did Elizabeth write to each correspondent?", theme =theme(plot.title =element_text(hjust =0.5)))
Code
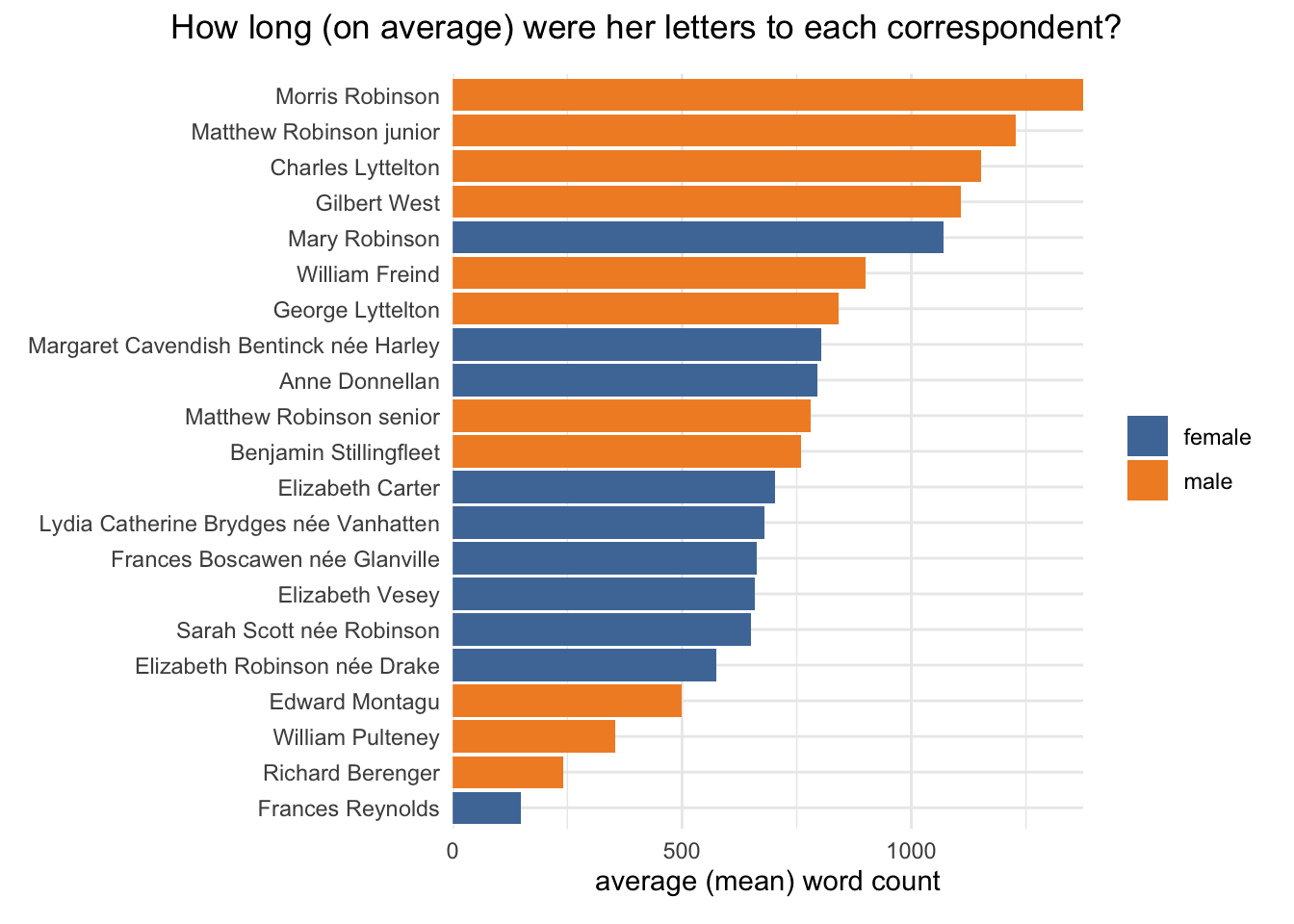
blue_metadata %>%group_by(recipient_short, recipient_gender) %>% dplyr::summarise(m =mean(n_words), s =sum(n_words)) %>%ungroup() %>%mutate(recipient_short =fct_reorder(recipient_short, m)) %>%ggplot(aes(x=recipient_short, y=m, fill=recipient_gender)) +geom_col() +coord_flip() +scale_y_continuous(expand =c(0,0)) +scale_fill_tableau() +labs(y ="average (mean) word count", x =NULL, fill=NULL) +plot_annotation(title="How long (on average) were her letters to each correspondent?", theme =theme(plot.title =element_text(hjust =0.5)))
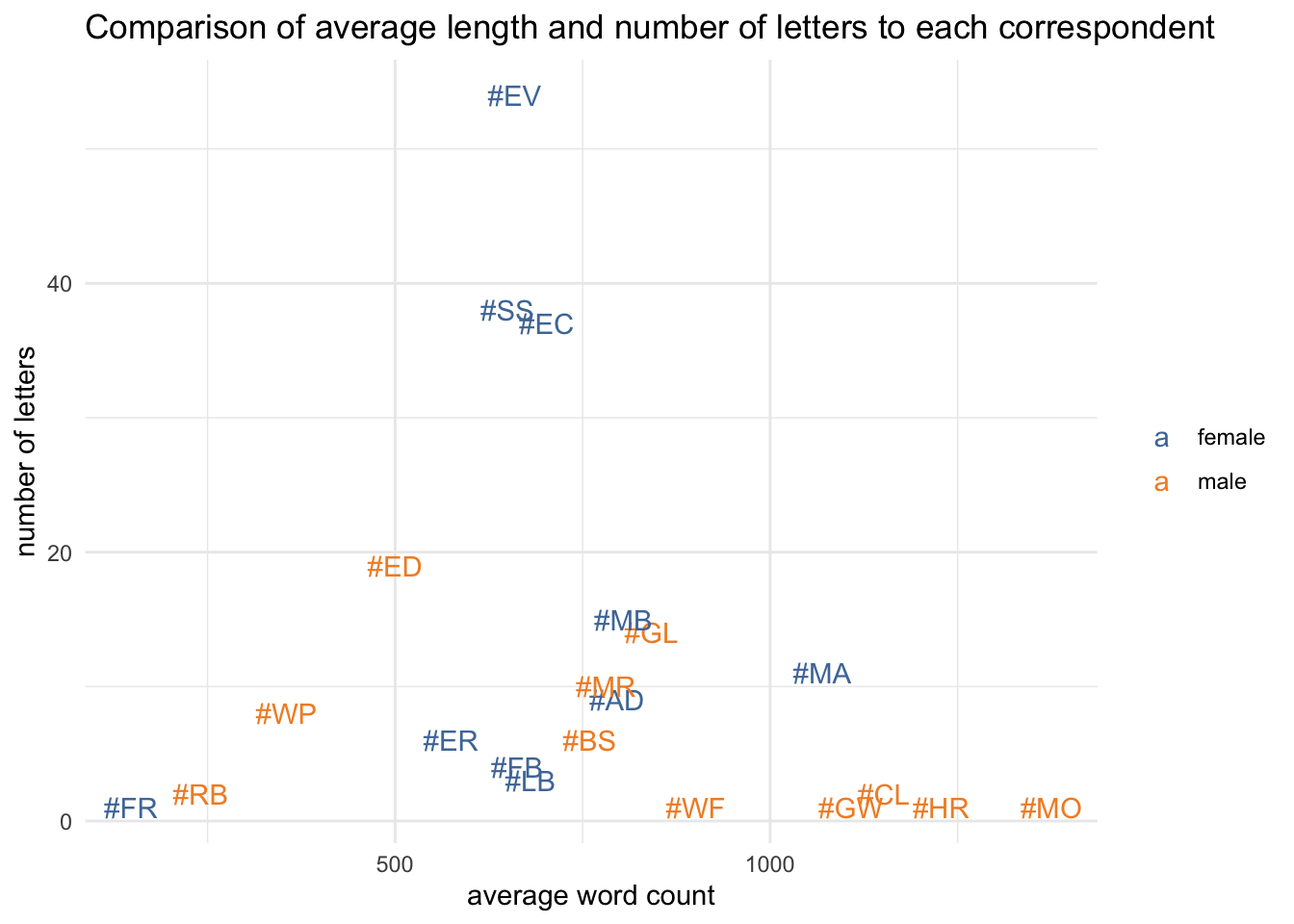
The differences raise a question: is there any kind of correlation between number of letters and average length?
There isn’t a simple pattern here; it’s clear that most letters to male correspondents are at the longer end of the spectrum, but they also tend to get the shortest letters. (The plot uses name codes for readability; the names are listed below.)
Code
blue_metadata %>%group_by(recipient_short, recipient_id, recipient_type, recipient_gender) %>% dplyr::summarise(mean_words =mean(n_words), med_words=median(n_words), total_words=sum(n_words), n_letters=n()) %>%ungroup() %>%ggplot(aes(x=mean_words, y=n_letters, colour=recipient_gender)) +geom_text(aes(label=recipient_id)) +scale_color_tableau() +labs(x="average word count", y="number of letters", colour=NULL, title="Comparison of average length and number of letters to each correspondent")
There are many sorts of questions you can explore using textmining; one involves looking for the most distinctive words in particular types or groups of documents.
A commonly used method for this is TF-IDF (Term Frequency Inverse Document Frequency). This helps to account for the fact that by far the most frequently used words in most corpora are “function words” (“the”, “and”, etc).
The idea of tf-idf is to find the important words for the content of each document by decreasing the weight for commonly used words and increasing the weight for words that are not used very much in a collection or corpus of documents… Calculating tf-idf attempts to find the words that are important (i.e., common) in a text, but not too common.
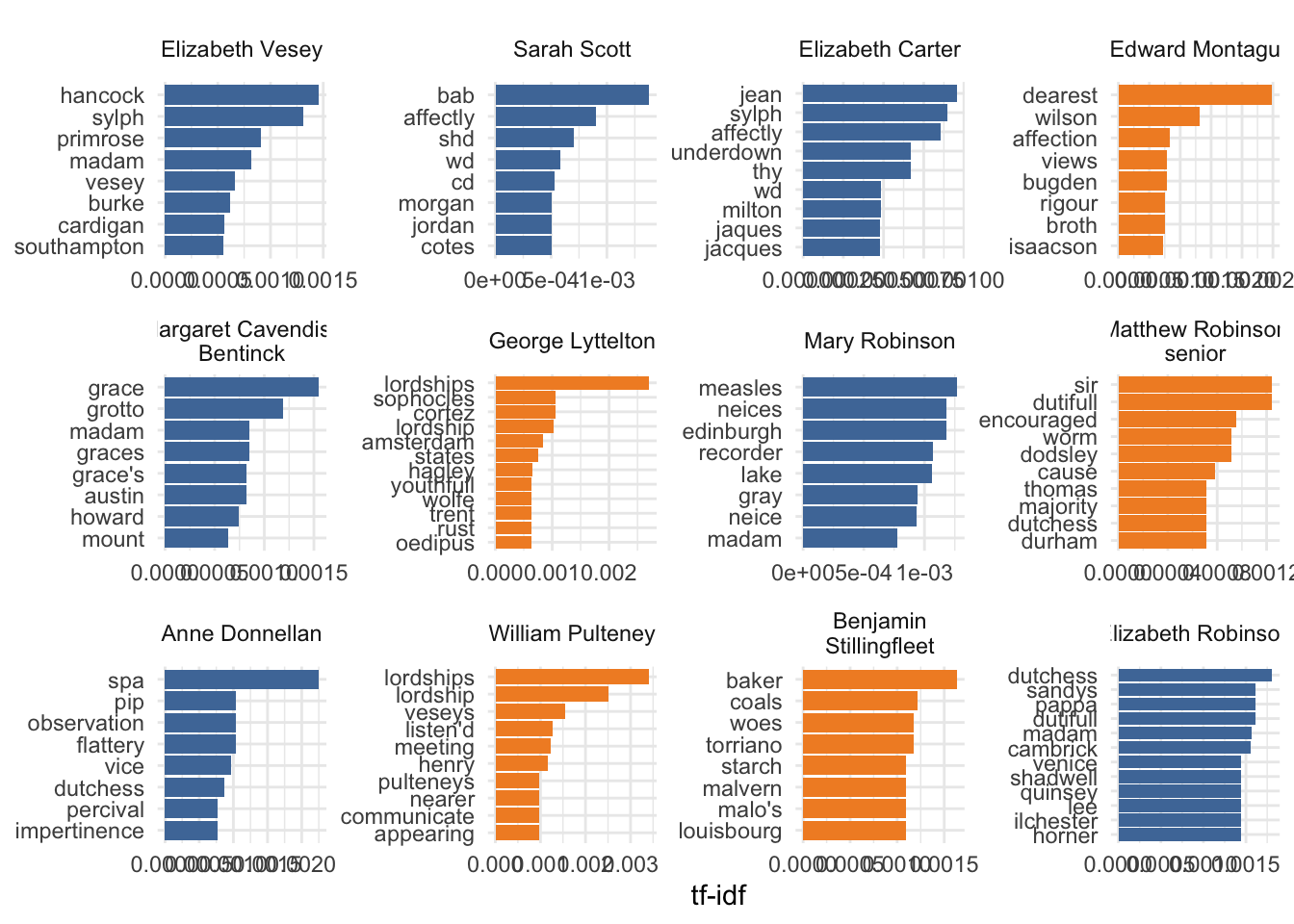
So it can be useful for looking at particularly distinctive words in letters to individual correspondents (this is restricted to 12 people who were sent at least 6 letters, and to the top 8 words - if there are more than 8 it’s because there’s a tie). There are some interesting differences. Most of the top 8 words to Elizabeth Vesey are people’s names; that’s also true of letters to Elizabeth Carter but they’re names like “Milton”, “Jean” and “Jacques/Jaques” (Jean Jacques Rousseau? closer reading needed at this point!). Letters to Mary Robinson are talking about “nieces” and “measles” (again, could there be a direct connection?); letters to Anne Donnellan seem unusually concerned with morality and behaviour (“flattery”, “vice”, “impertinence”); and letters to Benjamin Stillingfleet with more practical topics (“baker”, “coals”, “starch”).
It’s important to bear in mind that these reflect only part of all the things that Elizabeth might have written to those people about, but they may be pointing to significant differences that are worth further conventional close-reading investigation. (Conversely, you might use textmining to look for the greatest similarities between letters to different correspondents.)
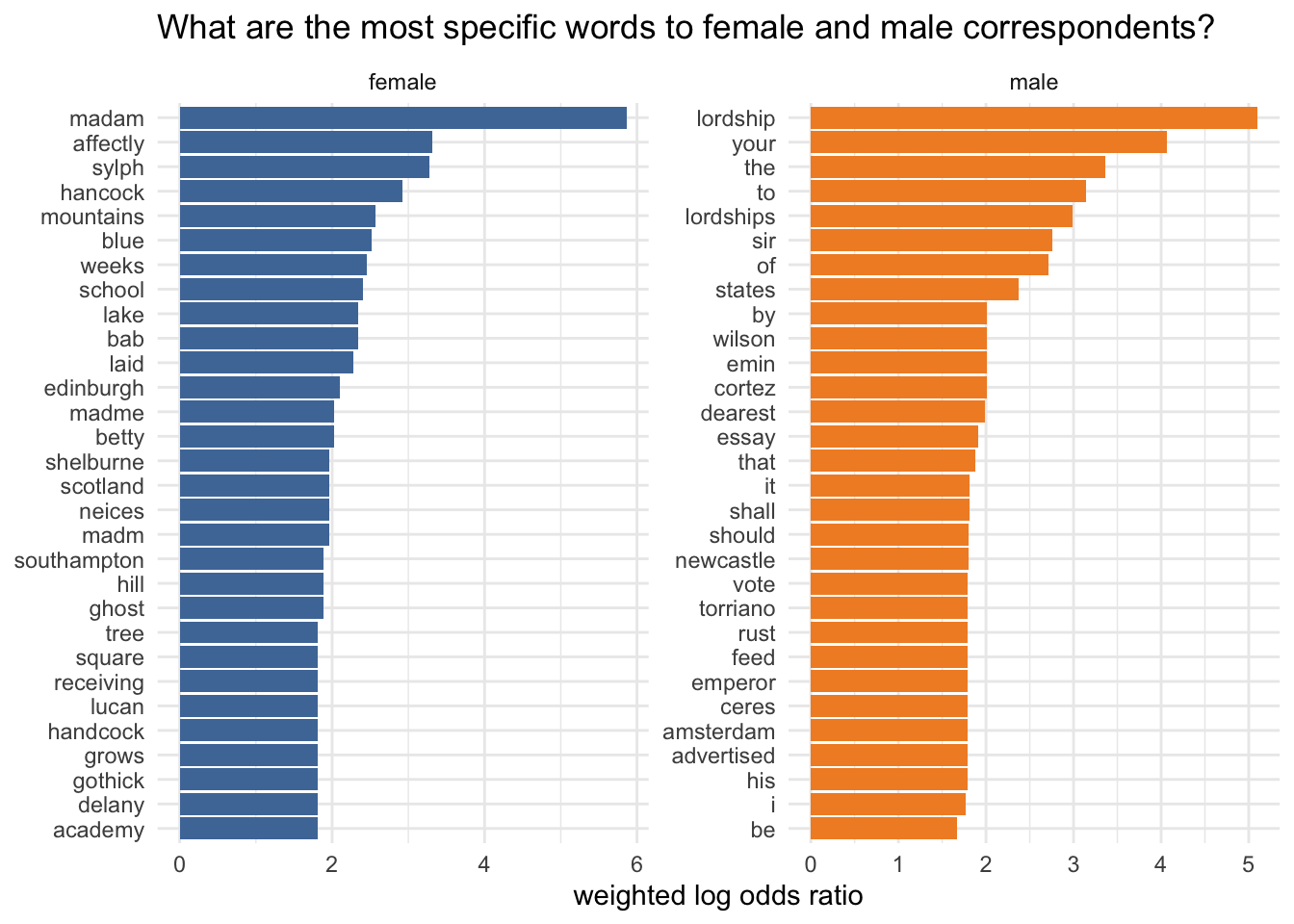
An alternative method for measuring distinctiveness is weighted log odds ratios. While TF-IDF is very popular, there are some problems with using it for this kind of analysis:
One of the problems with using tf-idf for stylistic analysis is that if everyone uses them they’ll get a score of 0 even if some people use them a whole lot more than others.
That’s obviously a particular issue if I’m trying to compare a small number of grouped documents - “male” and “female”.
In fact I’m not sure how well log odds ratios work in this particular case; though there are some potentially interesting differences, some seem too obvious to provide much insight. But perhaps it is telling us something less obvious: the fact that there are a lot of “function” words on both sides (“she” and “her” at the top of the female side, for example) may be suggesting that the content of Elizabeth’s letters is not that strongly gendered. That is to say, she doesn’t write to men and women about massively different things, although there may be a slight lean towards domestic and leisure (“home”, “mountains”, “lake”) on the female side, and towards literary and politics on the male side (“critical” and “critick”, “interest”, “county”).
Code
blue_gender_log_odds %>%arrange(-log_odds_weighted) %>%#filter(!word %in% stop_words_s$word) %>%group_by(recipient_gender) %>%top_n(30, log_odds_weighted) %>%ungroup() %>%mutate(word =reorder_within(word, log_odds_weighted, recipient_gender)) %>%ggplot(aes(word, log_odds_weighted, fill=recipient_gender)) +geom_col(show.legend =FALSE) +facet_wrap(~recipient_gender, ncol =2, scales ="free") +scale_fill_tableau() +scale_x_reordered() +coord_flip() +labs(y="weighted log odds ratio", title="What are the most specific words to female and male correspondents?", x=NULL)
Social networks
People’s names have not been tagged in the letters. However, Elizabeth tends to refer to people using their titles which makes it possible to extract the majority of individuals’ names on this basis. (The titles searched for are as follows: “Miss”, “Mrs”, “Mr”, “Lord”, “Ld”, “Lady”, “Ldy”, “Dr”, “Sir”, “Sr”, “Duke of”, “Duchess of”, “Dutchess of”, “Countess of”, “Earl of”.)
Obviously this is unsatisfactory compared to manually tagging names:
the method misses a small (I think…) number of names without titles (I think these might tend to be children and lower status individuals like servants?)
I’ve omitted some titles that are much less common and often don’t refer to contemporary individuals (eg King, Queen, Prince, Princess)
I’ve made no attempt to disambiguate people! The same person can be called by more than one name; more than one person may have the same name
I count only one mention of a unique name per letter, but this doesn’t account for the use of slightly different names for the same person in a letter (eg full name on first mention, shorter form later, or variations in spelling)
I’ve made no attempt to identify whether mentioned names are also correspondents
However the advantage of extracting names in this way is that (with a bit of experimentation and cleaning up), it can be done in a few hours whereas manual tagging would be a substantial project. I think it has identified the majority of people mentioned in the letters, and is at least useful for an exploratory analysis.
Total distinct names found = 2321; after counting once per letter = 1859
Once again, there are some clear differences between letters to women and to men.
The most frequently mentioned name (and the name mentioned to the most recipients, though I’m not showing that here) is Mr Montagu. Several other top names are presumably also Elizabeth’s regular correspondents - Mrs Carter, Mrs Vesey, Mrs Donnellan, etc.
Another popular name - with both female and male recipients - is Lord Lyttelton. But it’s noticeable that in letters to female recipients, a much higher proportion of names mentioned here are female (17 of 23, vs only 6 of 23 in letters to male recipients).
Does that pattern extend to all names mentioned rather than just the most common ones? Overall the gender of mentioned names in letters to women ends up quite evenly balanced, but only 25% of names mentioned in letters to men are female.
A closer look at names mentioned to Elizabeth’s most written-to female correspondents shows not only differences in their networks, but also intriguing differences in mentions patterns. An extremely high proportion of the names in letters to Margaret Cavendish Bentinck are only mentioned once (which is why her graph looks such a mess and you can’t read any of them properly…). This happens to some extent with Anne Donnellan as well, but she was sent only 9 letters compared to Margaret’s 15, and it’s much less extreme with Mary Robinson (who was sent 11 letters).
Code
blue_names %>%distinct(name, recipient_short, docid) %>%# dedupe per lettercount(name, recipient_short, sort=TRUE) %>%group_by(recipient_short) %>%mutate(s=sum(n), pc = n/sum(n)*100) %>%top_n(12, n) %>%ungroup() %>%inner_join(blue_recipients %>%filter(n_letters>8, recipient_gender=="female") %>%select(recipient_short, n_letters) , by="recipient_short") %>%mutate(recipient_short =str_replace(recipient_short, " *née.*$", "")) %>%#arrange(recipient_id, desc(pc))mutate(name =reorder_within(name, n, recipient_short)) %>%mutate(recipient_short =fct_reorder(recipient_short, -n_letters)) %>%ggplot(aes(name, n, fill=recipient_short)) +geom_col(show.legend =FALSE) +facet_wrap(~recipient_short, ncol =3, scales ="free", labeller=labeller(recipient_short=label_wrap_gen(19)) ) +scale_fill_tableau() +scale_x_reordered() +coord_flip() +labs(x=NULL, y="mentions") +plot_annotation(title="Most frequently mentioned names in letters to top 6 female correspondents", theme =theme(plot.title =element_text(hjust =0.5)))
Which names are most connected?
This correlation plot visualises the correlations between the most frequently mentioned names in letters to female correspondents. The darker the shade, the stronger the positive (red) or negative (blue) association. (A score of +1 would mean that two names always appear together, and a score of -1 that they always appear separately.)
Because it’s so compact it needs to be read with some care. As an example, for Mrs Vesey you’d read down and then across to see that she’s most strongly positively connected with Lady Primrose and most negatively correlated with Lady Bab. Interestingly, Mr Montagu, who we know is more frequently mentioned than anyone else, isn’t very positively correlated with anyone (except perhaps Lady Bab). This may simply be because he’s mentioned so often, but it might alternatively suggest that letters about him are less likely to mention other people.
Code
cor(blue_names_top_fr_tab) %>% GGally::ggcorr(layout.exp =3.5, hjust =0.9, size =3.5, low ="#30305b", mid ="#fcfcfc", high ="darkred") +labs(title ="Correlation plot of most frequently mentioned names (female recipients only)")
Since I’m talking about social networks, I’ll finish up with a classic network graph. Again, this includes only letters to female correspondents, and is restricted to relatively strong connections; the darker the line, the stronger the correlation between individuals.
Social networks
People’s names have not been tagged in the letters. However, Elizabeth tends to refer to people using their titles which makes it possible to extract the majority of individuals’ names on this basis. (The titles searched for are as follows: “Miss”, “Mrs”, “Mr”, “Lord”, “Ld”, “Lady”, “Ldy”, “Dr”, “Sir”, “Sr”, “Duke of”, “Duchess of”, “Dutchess of”, “Countess of”, “Earl of”.)
Obviously this is unsatisfactory compared to manually tagging names:
However the advantage of extracting names in this way is that (with a bit of experimentation and cleaning up), it can be done in a few hours whereas manual tagging would be a substantial project. I think it has identified the majority of people mentioned in the letters, and is at least useful for an exploratory analysis.
Total distinct names found = 2321; after counting once per letter = 1859
Once again, there are some clear differences between letters to women and to men.
Code
What are the most commonly mentioned names?
The most frequently mentioned name (and the name mentioned to the most recipients, though I’m not showing that here) is
Mr Montagu. Several other top names are presumably also Elizabeth’s regular correspondents -Mrs Carter,Mrs Vesey,Mrs Donnellan, etc.Another popular name - with both female and male recipients - is
Lord Lyttelton. But it’s noticeable that in letters to female recipients, a much higher proportion of names mentioned here are female (17 of 23, vs only 6 of 23 in letters to male recipients).Code
Does that pattern extend to all names mentioned rather than just the most common ones? Overall the gender of mentioned names in letters to women ends up quite evenly balanced, but only 25% of names mentioned in letters to men are female.
Code
A closer look at names mentioned to Elizabeth’s most written-to female correspondents shows not only differences in their networks, but also intriguing differences in mentions patterns. An extremely high proportion of the names in letters to Margaret Cavendish Bentinck are only mentioned once (which is why her graph looks such a mess and you can’t read any of them properly…). This happens to some extent with Anne Donnellan as well, but she was sent only 9 letters compared to Margaret’s 15, and it’s much less extreme with Mary Robinson (who was sent 11 letters).
Code
Which names are most connected?
This correlation plot visualises the correlations between the most frequently mentioned names in letters to female correspondents. The darker the shade, the stronger the positive (red) or negative (blue) association. (A score of +1 would mean that two names always appear together, and a score of -1 that they always appear separately.)
Because it’s so compact it needs to be read with some care. As an example, for
Mrs Veseyyou’d read down and then across to see that she’s most strongly positively connected withLady Primroseand most negatively correlated withLady Bab. Interestingly,Mr Montagu, who we know is more frequently mentioned than anyone else, isn’t very positively correlated with anyone (except perhapsLady Bab). This may simply be because he’s mentioned so often, but it might alternatively suggest that letters about him are less likely to mention other people.Code
Since I’m talking about social networks, I’ll finish up with a classic network graph. Again, this includes only letters to female correspondents, and is restricted to relatively strong connections; the darker the line, the stronger the correlation between individuals.
Code