This is the second of a two-part series about the Westminster Coroners’ Inquests data. See part 1 for more detail about the source of the data, and my initial explorations of the summary data.
This post focuses more on the text of inquisitions (the formal legal record of the inquest’s findings and verdict). An example here. I’ll also use the verdicts data, so that I can compare texts in each verdict category.
Undetermined is a small verdict category, and I’m going to exclude it from most analysis because I think it’s likely to be confusingly miscellaneous. (OK, and because it’s easier to fit 4 categories into plots.)
Code
# r packages library(tidyverse)theme_set(theme_minimal()) # set preferred ggplot theme library(lubridate) # nice date functionslibrary(scales) # additional scaling functions mainly for ggplot (eg %-ages)library(knitr) # kable (nicer tables)library(kableExtra) library(readtext)library(tidytext)library(tidylo) library(quanteda)library(patchwork)library(ggthemes)# inquest texts data inquest_texts_data <-readtext(here::here("site_data/wa_inq_txt/*.txt"),docvarsfrom ="filenames",dvsep ="txt",docvarnames =c("img_inq_first"))# inquest texts -> tibble format #inquest_texts_data <- as_tibble(inquest_texts_data) # summary data cw_summary_data <-read_tsv(here::here("site_data/wa_coroners_inquests_v1-1.tsv"), na="NULL", col_types =cols(doc_date =col_character()) )# prep summary data ## add new columns# inquest_add_type: child, prisoner, multi, none # name type named/unnamed # clean up doc dates (a couple end -00-> -01), then add doc year, doc month# simplify verdict - merge suicides# parish names: "St Ann" -> "St Anne Soho" ## note on joining summary to texts data# first_img and inquisition_img are both prefixed WACWIC -> eg WACWIC652000003_WACWIC652000002 # but texts ID (from filename) = WACWIC652000003_652000002 ## filter out # unknown/mixed gender and type multi# unknown verdict (not the same as 'undetermined')# a random inquest date before 1760 (2891) which I CBA to look upcw_summary <- cw_summary_data %>%rename(verdict_original = verdict) %>%mutate(gender =case_when( gender =="f"~"female", gender =="m"~"male",TRUE~ gender),inquest_add_type =case_when(str_detect(deceased_additional_info, "child") ~"child",str_detect(deceased_additional_info, "p[ri]+soner") ~"prisoner", # found a typo lolstr_detect(deceased_additional_info, "multiple") ~"multiple",TRUE~"none"),name_type =ifelse(!str_detect(the_deceased, regex("unnamed", ignore_case=TRUE)), "named", "unnamed") ,age_type =ifelse(inquest_add_type =="child", "child", "adult"),doc_date =as_date(str_replace(doc_date, "00$", "01")),doc_year =year(doc_date),doc_month =month(doc_date, label =TRUE),parish =ifelse(parish =="St Ann", "St Anne Soho", parish),verdict =ifelse(str_detect(verdict_original, "suicide"), "suicide", verdict_original) ) %>%mutate(first_img_no =str_replace(first_img, "WACWIC","")) %>%unite(img_inq_first, inquisition_img, first_img_no, remove=FALSE) %>%filter(doc_year >1759, str_detect(gender, "male"), !str_detect(deceased_additional_info, "multi"), verdict !="-") # join texts to summary data # inner join excludes a handful which don't have text (not survived/no image/not rekeyed)cw_inquest_texts <- cw_summary %>%select(img_inq_first, doc_date, doc_year, doc_month, gender, verdict, inquest_add_type, name_type, age_type, inquisition_img) %>%inner_join(inquest_texts_data, by="img_inq_first") # tokenize unchopped versions cw_inquest_text_words_full <- cw_inquest_texts %>%unnest_tokens(word, text)
I began analysing the texts with some simple word counting in part 1, but before digging deeper, I need to do some additional work. It’s often noted that, however sophisticated your data analysis techniques, most of the work is preparing and cleaning your data first, and getting this (often very boring) process right is crucial to getting valid results.
A big problem with the inquisitions is that the amount of content actually describing the circumstances of a death is often a very small proportion of the document as a whole. This can be divided into two distinct issues:
large blocks of text which don’t vary between texts (I’ll call them “boilerplate”) and can therefore be discarded in their entirety to get them out of the way
frequently used words or short phrases; in this case, not so much what linguists call “function words” (like “the” “or” “and”) as formulaic legal and bureaucratic language.
Here’s one of the texts:
Code
# to print code result as blockquote text: results='asis' and cat() cat(paste0("> ", cw_inquest_texts %>%filter(inquisition_img =="WACWIC652370118") %>%pull(text) ) )
City and Liberty of Westminster , In the County of Middlesex ,} to wit, An Inquisition Indented, taken for our Sovereign Lord the King, at the House of Richd. Tyler Chapel Street oxford Street Parish of Saint Anne Soho within the Liberty of the Dean and Chapter of the Collegiate Church of St. Peter, Westminster , in the County of Middlesex , the twentieth day of February 1797 in the thirty Seventh Year of the Reign of our Sovereign Lord GEORGE the Third, by the Grace of God, of Great-Britain, France, and Ireland King, Defender of the Faith, and so forth, before Anthony Gell , Esq. Coroner of our said Lord the King for the said City and Liberty, on View of the Body of Humphris Jones then and there lying dead, upon the Oath of the several Jurors whose Names are here under written, and Seals affixed, good and lawful Men of the said Liberty, duly chosen, who being then and there duly sworn and charged to enquire for our said Lord the King, when, how, and by what Means the Said Humphris Jones came to his Death, do upon their Oath say that, the Said Humphis Jones, on the nineteenth day of February in the Year aforesaid in Oxford Street Street in the County of Middlesex died, by the Visitation of God in a natural Way To Wit of an Apoplexey of god and not otherwise
IN WITNESS whereof, as well the said Coroner as the said Jurors, have to this Inquisition set their Hands and Seals the Day, Year, and Place first above written.
Anthy. Gell Coroner } Wm Daviesford John Hamstead Willm Hall Wim Webster John Bell
Jas Cragg Thos Gibson W Knightlie George John Yare Joseph Wm Walker
boilerplate
There are two large chunks of text that are almost the same in every inquisition: everything from the beginning to “do upon their oath say That”, and from “IN WITNESS whereof” to the end. The only variations within these sections are a) the insertion of the names of the deceased, jurors, dates and parish in which the death occurred (all useful data, but not relevant to the current analysis); and b) the jurors’ names may be listed in the first chunk or at the very end of the second. These conventions were so well-established that many of the inquisitions are on pre-printed forms (including the example above).
Code
## top-and-tail: remove unwanted formulaic text sections at beginning and end # these are not exactly the same in each document ## a) they contain inserted text, mainly names/dates; b) slight variations in wording and/or rekeying# but as it turns out, apart from the names, there isn't *much* variation# possibly unnecessary over-complication, but only use second set of regexes on texts for which the first set have failed # the end segment can be located by "in witness whereof" in nearly all cases;# reg_end1 deals with all bar 10; 1 of the remaining seems to be truncated anyway; reg_end2 gets the rest# don't seem to be any problems with the output, though it's hard to test...reg_end1 <-"(\\bin +)?(win?th?ne?ss(es)?[[:punct:]]?) +([stw]?here[[:punct:]]? *of|w[eh]+re? *of|whereby|when *of|where *as|when, as well|where was well)"#to mop up the remainderreg_end2 <-"(in witness( of as well| of the said| foreman of))|((and|the) said coroner as)|((whereof )?as well( as)? the said coroner)|(musson foreman of the said jurors)|(and not coroner as the said)"# to remove the start...# "... upon their oath(s) say" cover nearly everything, just need to account for a few typos# checked the results and doens't seem to strip anything it shouldn'tstart_reg1 <-"(up *on,? *their *[co]aths?( +say)?|(open|do) *their *oath *say|upon *then? *oath say)"# this works for mopping upstart_reg2 <-"by what means the said"# process# str_split , limit to 2# map_chr to extract 2nd element of split; .null catches fails cw_inquest_texts_stripped <- cw_inquest_texts %>%select(img_inq_first, text) %>%mutate(text_split_reg_e1 =map_chr( str_split(text, regex(reg_end1, ignore_case =TRUE), n=2) , 1, .null=NA_character_),text_split_reg_e1_test =map_chr( str_split(text, regex(reg_end1, ignore_case =TRUE), n=2) , 2, .null=NA_character_),text_split_reg_e2_test =map_chr( str_split(text, regex(reg_end2, ignore_case =TRUE), n=2 ), 2, .null=NA_character_) ) %>%mutate(text_stripped_end =case_when(!is.na(text_split_reg_e1_test) ~ text_split_reg_e1, !is.na(text_split_reg_e2_test) ~map_chr( str_split(text, regex(reg_end2, ignore_case =TRUE), n=2 ) , 1, .null=NA_character_),TRUE~ text ) ) %>%select(-text_split_reg_e1:-text_split_reg_e2_test) %>%mutate(text_split_reg1 =map_chr(str_split(text_stripped_end, regex(start_reg1, ignore_case =TRUE), n=2) , 2, .null =NA_character_),text_split_reg2 =map_chr(str_split(text_stripped_end, regex(start_reg2, ignore_case=TRUE), n=2) , 2, .null =NA_character_),text =if_else(!is.na(text_split_reg1), text_split_reg1, text_split_reg2) ) %>%select(-text_split_reg1, -text_split_reg2, -text_stripped_end) %>%left_join(cw_summary, by="img_inq_first")# tokenize texts - top+tailed versioncw_inquest_text_words <- cw_inquest_texts_stripped %>%unnest_tokens(word, text)
In fact, in many inquisitions the boilerplate accounts for most of the text: the average length of the remaining text is only 148.5 words.
So it makes sense and is fairly straightforward to get rid of this stuff entirely before analysing the texts. (The gory details are in the R code.) Here’s what the stripped version of the first example looks like:
Code
# to print code result as blockquote text: results='asis' and cat() cat(paste0(">", cw_inquest_texts_stripped %>%filter(inquisition_img =="WACWIC652370118") %>%pull(text)) )
that, the Said Humphis Jones, on the nineteenth day of February in the Year aforesaid in Oxford Street Street in the County of Middlesex died, by the Visitation of God in a natural Way To Wit of an Apoplexey of god and not otherwise
From here onwards I’ll use the texts with the boilerplate removed.
stopwords
The legal formula and locally specific words necessitated the compilation of a custom stopwords list (again the details can be seen in the code). This discussion is included mainly to highlight how the construction of stopwords for textmining a historical corpus can’t be a one-size-fits-all exercise. You might start with a generic function words list, but to do serious analysis you’ll need to dig into your specific dataset and understand something about its historical context.
Some of the legal terms aren’t obvious without knowledge of the texts and which are very context dependent. For example, I know that in inquisitions “said” is not referring to people talking, but appears in phrases like “by what Means the Said Humphris Jones came to his Death” and is a synonym for “aforesaid”. In this set of texts, I also know that words like “county”, city”, “parish”, “liberty” (that’s an administrative unit, not the abstract ideal) or “oath” are not content words as they might be in many corpora. To this I can add words like “jurors”, “died” and “death”, “Middlesex” and “Westminster”.
There’s a final set of words I want to remove from analysis: people’s first names. This again is highly context-dependent. If you’re mining the novels of Jane Austen, people’s given names are significant. But in this case the names of individuals are not meaningful (and, to make things worse, 18th-century Londoners were not very creative when it came to naming their children). Fortunately, I already have name data in the shape of the London Lives tagged XML, which I can use to make a custom dictionary.
Top words in verdict categories
The first post on the inquests showed a number of significant differences in the character of inquests and outcomes by analysing the summary data and word counts in part 1. It seems more than likely that the language used in association with the different verdicts will vary significantly too. What can comparisons of the “top” words in each verdict tell us?
But there are different ways of thinking about “top words” and I’m going to compare three of them:
I start by building a corpus, to which I apply my stopwords. Then I can use ggplot to compare the top word frequencies for each category.
Code
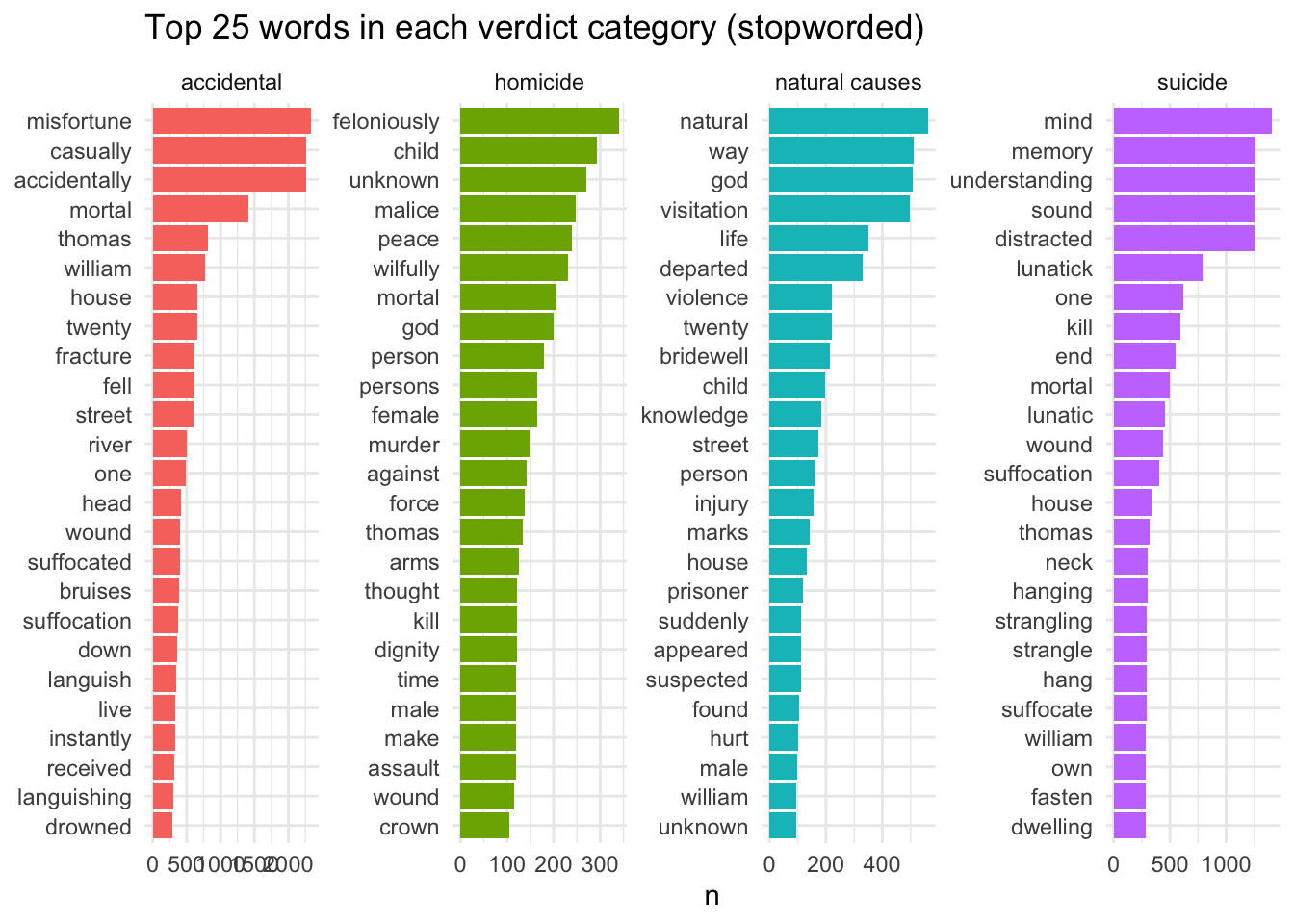
## quantedacw_verdicts_corpus <-corpus(cw_inquest_texts_stripped %>%filter(verdict !="undetermined") %>%select(img_inq_first, text, verdict, doc_date, gender),text_field ="text", docid_field ="img_inq_first")cw_verdicts_dfm <-dfm(cw_verdicts_corpus, remove_punct=TRUE#, groups="verdict" ) %>%dfm_group(groups=verdict)# grouped dfm with stopwords removedcw_verdicts_dfm_s <-dfm(cw_verdicts_corpus, remove_punct=TRUE, remove=custom_stopwords #, groups="verdict") %>%dfm_group(groups = verdict)library(quanteda.textstats)#textstat_frequency(dfm, n = 5, groups = "lang")cw_verdicts_freq <-textstat_frequency(cw_verdicts_dfm_s, n=25, groups=verdict)cw_verdicts_freq %>%mutate(feature =reorder_within(feature, frequency, group)) %>%ggplot(aes(feature, frequency, fill=group)) +geom_col(show.legend = F) +facet_wrap(~group, ncol=4, scales="free") +coord_flip() +scale_x_reordered() +labs(x =NULL, y ="n", title ="Top 25 words in each verdict category (stopworded)")
This is pretty good. There are clear differences between the verdict categories. In each category, there are various words that are part of legally required key phrases:
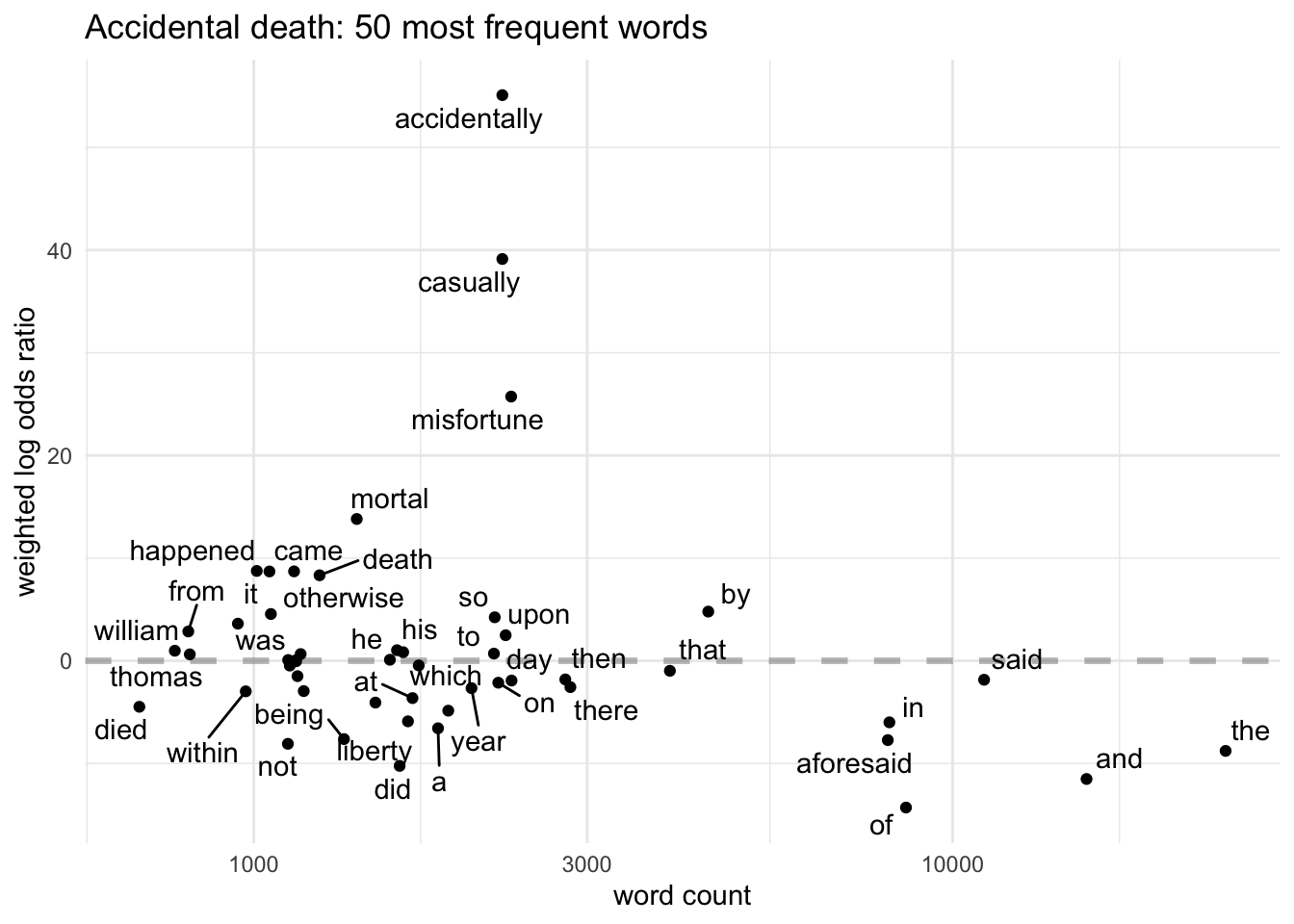
In the accidental deaths category, many of the top 30 words are immediately revealing, referring directly to causes of death - drowning (and thames), suffocation, carts and horses; ground almost certainly alludes to falls - suggesting that these are the most common causes of accidental deaths. People might die instantly or languish/live for a while (perhaps dying in hospital if so).
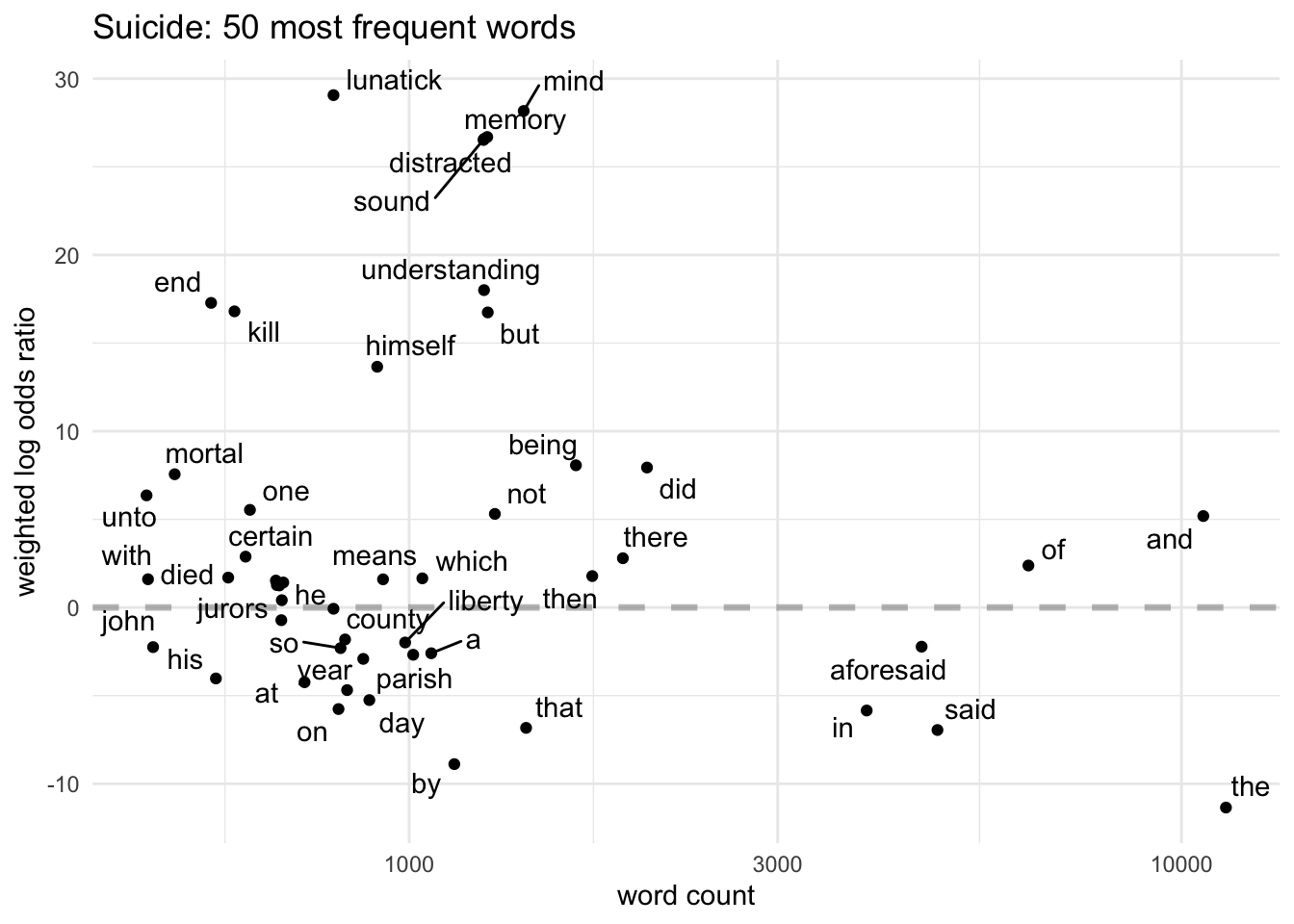
Many suicide category words, too, are grimly descriptive - suffocation, hanging, strangling, neck, throat, fasten and fix. (Perhaps iron and piece are less immediately obvious?) This suggests that the majority of suicides in later 18th-century London were by hanging.
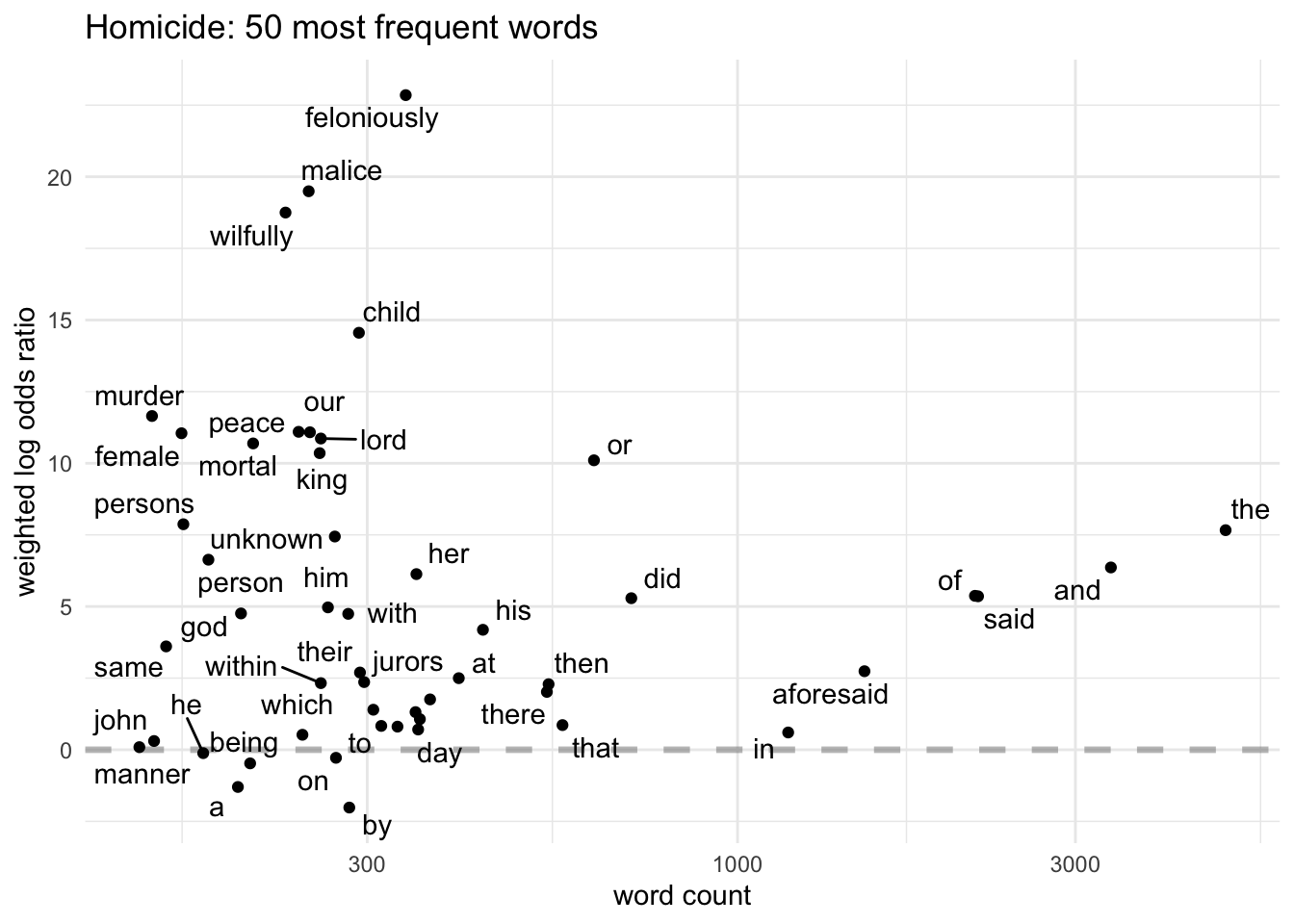
In contrast, the words for homicide seem - surprisingly - much less evocative. Languish/live turn up again but apart from that we don’t really get beyond legal phrases (“make an assault”, “malice aforethought”, “moved/seduced by the devil”, and so on). This suggests a couple of things. There is probably more legal verbiage in an inquisition with a homicide verdict because of the high likelihood that it will trigger a criminal prosecution (sometimes the inquisition might actually be used as a formal indictment at a later trial). And, for much the same reason, the rest of the language in homicide inquisitions is probably more detailed, and therefore more varied and less repetitious than in the other categories; remember that the first post has already shown that they’re the longest.
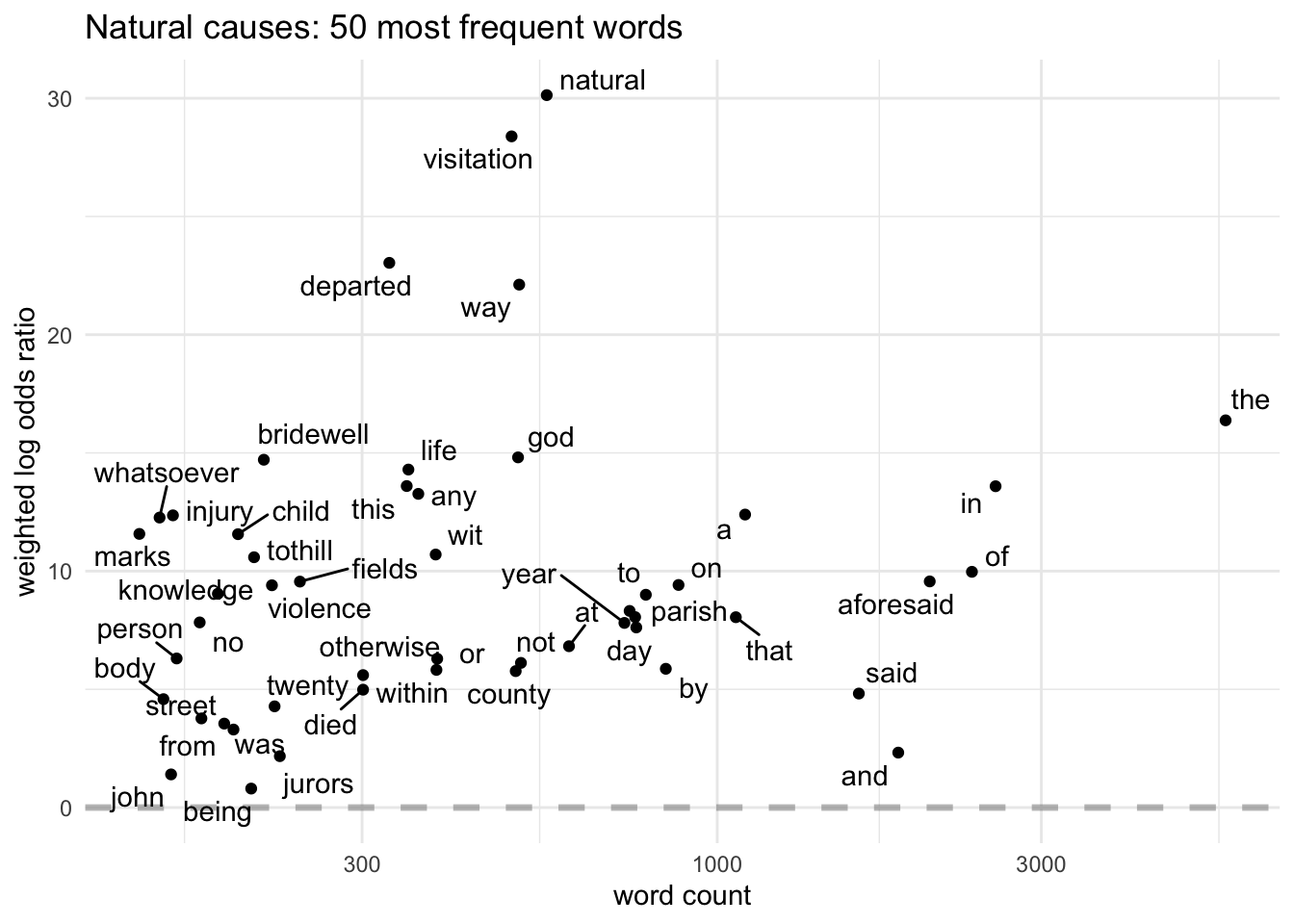
The top 30 in natural causes has some curious (at first sight) features. The reason bridewell (which was at Tothill Fields) is near the top is fairly straightforward: an inquest was automatically held for any prisoner who died in custody, and these almost always returned a verdict of natural causes. The presence of suspected, murdered and violent may at first seem odd, but they all point to the fact that inquests were often held because of local suspicions about a death. If nothing could be proved, the verdict would be natural causes.
Underlining the limitations of quantification without closer reading, unknown in homicide and in natural causes have quite different meanings: in homicides it almost always refers to an unknown perpetrator, but in natural causes it refers to the deceased and points to the number of natural causes inquests on poor “strangers” who had died of cold or starvation.
# tidy# count words by verdict, excluding undetermined cw_verdict_words <- cw_inquest_text_words %>%select(verdict, word) %>%filter(verdict !="undetermined") %>%# count of all words in verdict category (not unique words)add_count(verdict, name="total_v") %>%# count word in verdict categorycount(verdict, word, total_v, name="n_v", sort =TRUE) %>%ungroup()
So, a simple analysis of word frequencies has produced some interesting results. Well, not that simple. In order to get anywhere at all I had to laboriously compile stopword lists, which required considerable existing knowledge of this type of document, are very subjective, and really quite crude. Can I do better?
These problems can be addressed by “term frequency-inverse document frequency”, for which I’ll draw on the Tidy Text Mining tutorial.
Term frequency (tf) is simply the number of times a term (word) appears in a document.
Document frequency refers to the number of documents in a collection that contain a particular term. In the context of this post, “document”=“verdict category”, and “collection”= “all the inquisitions”.
Inverse document frequency (idf) reduces the weighting of terms that occur very frequently in a collection and increases the weighting of terms that rarely occur. So the idf of a rarely-used term is high, and the idf of a term that appears in every document is 0.
Finally, Term frequency-inverse document frequency (tf-idf) multiplies the term frequency by the inverse document frequency to get a score of the “importance” of each term.
The idea is that tf-idf for a term is:
highest when the term occurs many times in a very small number of documents
lower when the term occurs fewer times in a document, or occurs in many documents
lowest when the term occurs in virtually all documents. (source)
Code
# calculated output columns:# tf = term frequency# idf = inverse document frequency# tf_idf = term frequency-inverse document frequency (tf * idf)cw_verdict_tfidf_words <- cw_verdict_words %>%bind_tf_idf(word, verdict, n_v) %>%arrange(verdict, desc(tf_idf)) %>%group_by(verdict) %>%mutate(v_order =row_number()) %>%top_n(25, tf_idf) %>%ungroup()cw_verdict_tfidf_words %>%mutate(word =reorder_within(word, tf_idf, verdict)) %>%ggplot(aes(word, tf_idf, fill=verdict)) +geom_col(show.legend =FALSE) +facet_wrap(~verdict, ncol =4, scales ="free") +coord_flip() +scale_x_reordered() +labs(x =NULL, y ="tf-idf", title ="Top 25 tf-idf weighted words in each verdict category")
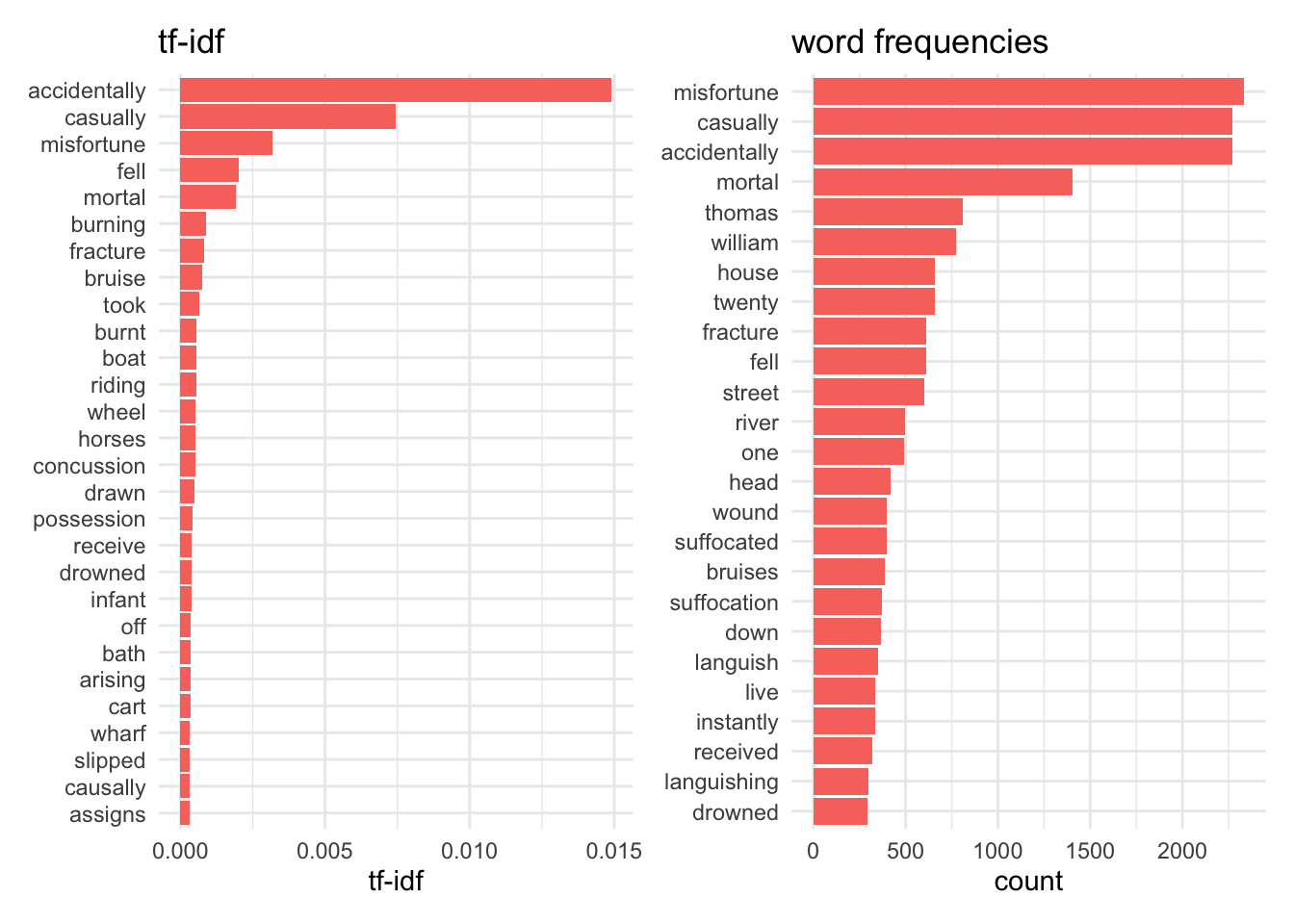
Some interesting differences! But that’s a lot to take in. Let’s zoom in and compare the stopworded top 25 to the tf-idf top 25 for the biggest category, accidental deaths.
Code
cw_verdict_tfidf_words %>%filter(verdict =="accidental") %>%mutate(word =fct_reorder(word, tf_idf)) %>%ggplot(aes(word, tf_idf, fill=verdict)) +geom_col(show.legend =FALSE) +coord_flip() +labs(x =NULL, y ="tf-idf", title ="tf-idf") +cw_verdicts_freq %>%filter(group =="accidental") %>%mutate(word =fct_reorder(feature, frequency)) %>%ggplot(aes(word, frequency, fill=group)) +geom_col(show.legend = F) +coord_flip() +labs(x =NULL, y ="count", title ="word frequencies") +plot_layout(ncol=2)
Even when the same words appear, tf-idf often ranks them rather differently. “Accidentally”, “casually” and misfortune still float to the top but are re-ordered because “accidentally” only appears in the accidental verdict category (so it has a high idf).
An interesting difference is that “boat” and “drowned” appear in the tf-idf list, versus “river” and “drowned” in the stopworded list and I think this may be related to the higher ranking of “fell” in tf-idf. From tf-idf we get the more specific information that people drowned by falling off boats, rather than telling us what kind of water they drowned in (which probably wasn’t always the river). Tf-idf has definitely brought up more specific cause of death words, such as burnt/burning, riding/horses.
But why has suffocated/suffocation disappeared? Is it really that insignificant? Remember that, if a term appears in all the categories, tf-idf automatically gives it a score of 0, even if its use is variable between categories. But it’s pretty easy for a word to appear in all four verdict categories and still be of significance.
Weighted log odds ratios can help to address my problem with TF-IDF.
One of the problems with using tf-idf for stylistic analysis is that if everyone uses [the terms being analysed] they’ll get a score of 0 even if some people use them a whole lot more than others. That’s because the “idf” in “tf-idf” is for inverse document frequency… The inverse document frequency is calculated as the natural log of the total number of documents (=authors, so 18) divided by the number of documents (authors) who use the phrase (in this case everyone uses it, so 18 again). The natural log of 18/18 = natural log (1) = 0. So you multiply the tf*0=0.
Code
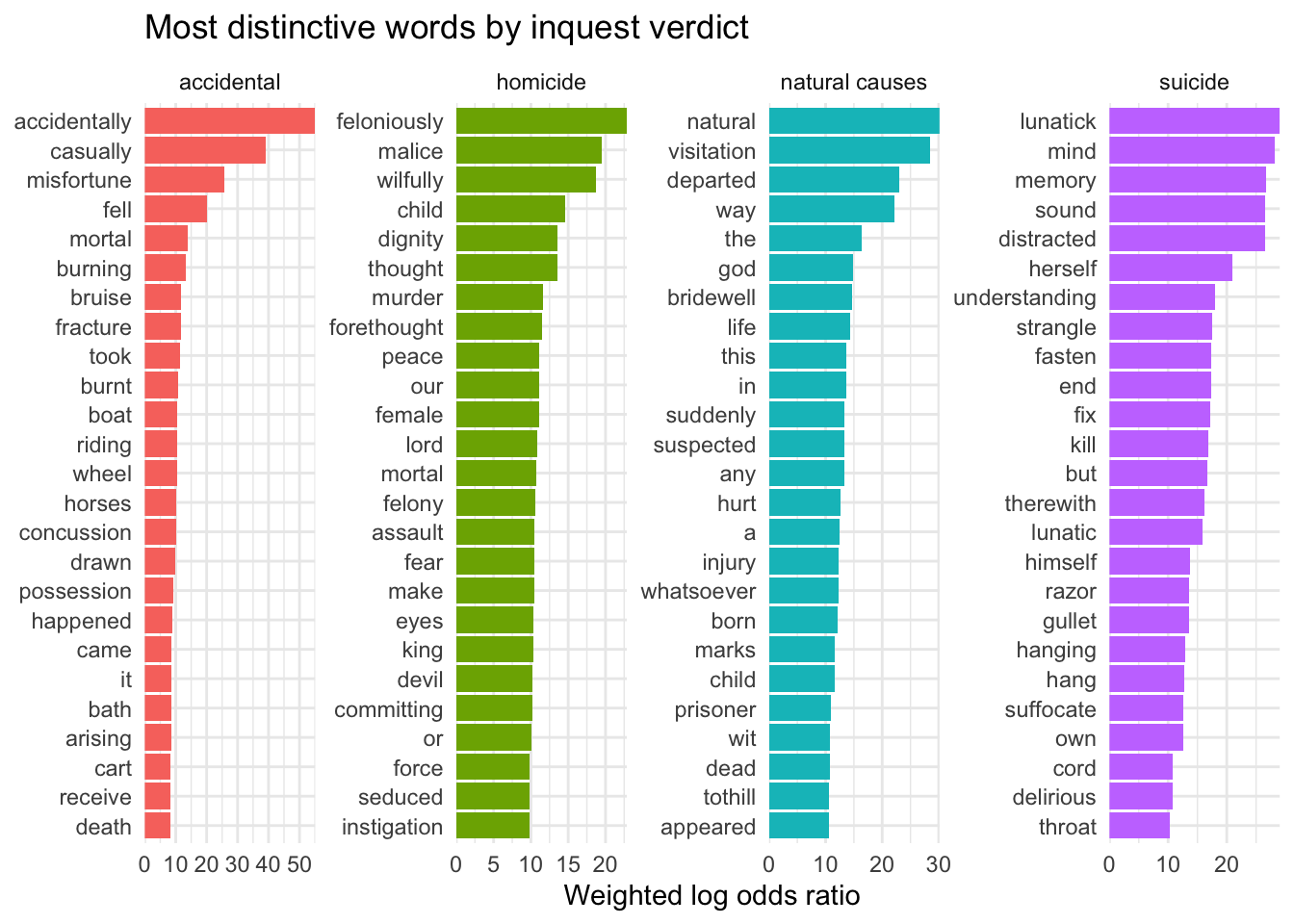
cw_verdicts_lo <-cw_verdict_words %>%bind_log_odds(verdict, word, n_v)cw_verdicts_lo %>%group_by(verdict) %>%top_n(25, log_odds_weighted) %>%ungroup() %>%mutate(word =reorder_within(word, log_odds_weighted, verdict)) %>%ggplot(aes(word, log_odds_weighted, fill = verdict)) +geom_col(show.legend =FALSE) +facet_wrap(~verdict, scales ="free", ncol=4) +coord_flip() +scale_x_reordered() +scale_y_continuous(expand =c(0,0)) +labs(y ="Weighted log odds ratio", x =NULL, title="Most distinctive words by inquest verdict")
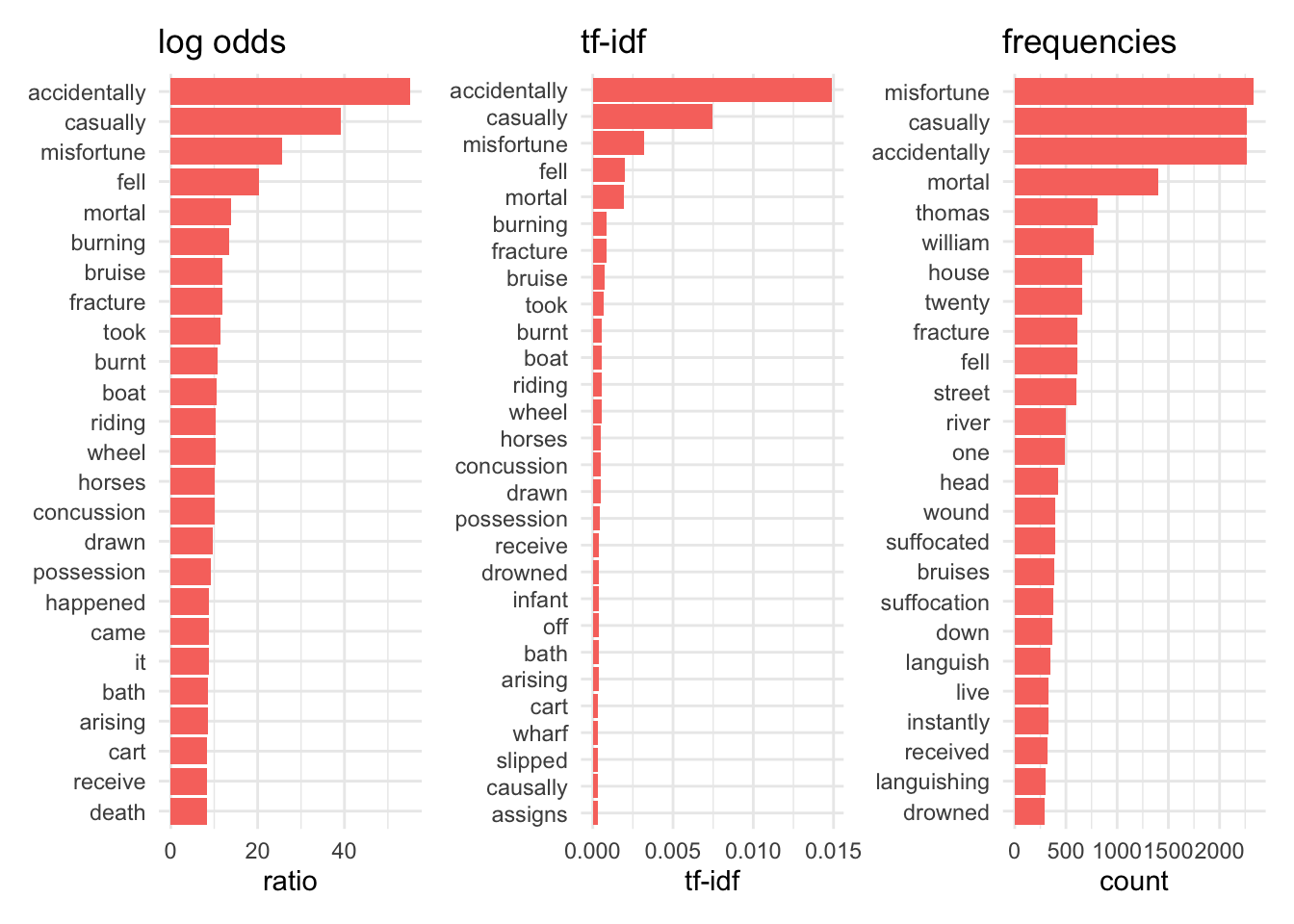
Now let’s compare all the results for accidental:
Code
cw_verdicts_lo %>%filter(verdict=="accidental") %>%top_n(25, log_odds_weighted) %>%mutate(word =fct_reorder(word, log_odds_weighted)) %>%ggplot(aes(word, log_odds_weighted, fill = verdict)) +geom_col(show.legend =FALSE) +coord_flip() +labs(y ="ratio", x =NULL, title="log odds") +cw_verdict_tfidf_words %>%filter(verdict =="accidental") %>%mutate(word =fct_reorder(word, tf_idf)) %>%ggplot(aes(word, tf_idf, fill=verdict)) +geom_col(show.legend =FALSE) +coord_flip() +labs(x =NULL, y ="tf-idf", title ="tf-idf") +cw_verdicts_freq %>%filter(group =="accidental") %>%mutate(word =fct_reorder(feature, frequency)) %>%ggplot(aes(word, frequency, fill=group)) +geom_col(show.legend = F) +coord_flip() +labs(x =NULL, y ="count", title ="frequencies") +plot_layout(ncol=3)
I’m quite pleased with the results of this exercise, not least because it suggests that I have at least two potentially helpful methods of text analysis that save me the slog of constructing stoplists. (Or, looked at from a different angle, could be used to help construct stoplists more easily.)
I’ll finish with a set of charts plot the log odds of the 50 most common words in each category, so I can look at some of the variations in more detail.